A era do Big Data e suas implicações para o acompanhamento macroeconômico
A velocidade com que tecnologias disruptivas têm sido lançadas neste século é estonteante e a capacidade de armazenamento e processamento explicam boa parte desta história. Nos últimos dois anos, por exemplo, foram produzidos mais dados que em toda a história da humanidade. O WITCH (Wolverhampton Instrument for Teaching Computing from Harwell), computador mais antigo em funcionamento e que começou a operar na década de 1950, pesa 2,5 toneladas e pode armazenar apenas 90 números. Empresas como o Dropbox oferecem hoje armazenamento ilimitado em planos que custam menos de US$ 10 por mês. Novas tecnologias, como o telefone, demoraram mais de 70 anos para atingir 50 milhões de pessoas, enquanto smartphones demoraram menos de 5 anos para atingir esta marca.
Segundo John Chambers (CEO da CISCO por 20 anos), 40% dos negócios irão falir em dez anos no Reino Unido: “Serão 50 bilhões de aparelhos conectados na internet das coisas em 2020 e 500 bilhões em 2030; isso vai mudar tudo”.
Os desafios que se apresentam para os próximos anos lançam dúvidas quanto a certos paradigmas do mundo de negócios contemporâneo. Charles O’Relly III e Michael Tushman, autores do best seller “Lead and Disrupt: How to Solve the Innovator's Dilemma”, defendem que só há um caminho para a empresa: ser ambidestro. Em linhas gerais, os autores argumentam que, para crescer, as empresas precisam criar vários processos que as tornem rígidas. Paradoxalmente, contudo, essa rigidez tem impedido as empresas de acelerar o processo de decisões e acompanhar o processo de mudança célere que estamos vivendo, tornando-as não competitivas.
No centro deste movimento está o conjunto de metodologias envolvidas no conceito geral de “Big Data”, que deve ser entendido em termos de três dimensões complementares: (i) novos paradigmas de obtenção de informações; (ii) algoritmos estatísticos concebidos em torno dos problemas de classificação, previsão e descobrimento de padrões, denominados de forma geral como algoritmos de “aprendizagem estatística” ou “aprendizado de máquina”; e (iii) novas estratégias computacionais.
Com relação aos “Novos paradigmas para a obtenção de dados”, a dimensão quantitativa da análise econômica sempre envolveu historicamente a coleta, a sistematização de armazenamento e a análise de variáveis relevantes para um amplo conjunto de questões. O conceito de informação vem se tornando muito mais diversificado à medida que a Internet passa a oferecer um conjunto gigantesco de dados de diferentes categorias: textos, imagens, mapas, redes sociais, sites de comércio eletrônico, além das tradicionais estatísticas numéricas. Essas informações são, em larga medida, complementos importantes para as bases tradicionais numéricas. Iniciativas de utilização dessas diferentes formas de dados já vêm sendo adotadas no Brasil e no mundo.
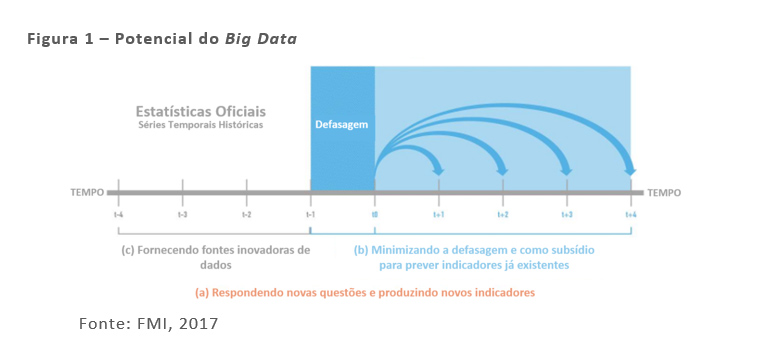
No último trimestre de 2017, o FMI lançou o documento intitulado “Big Data: Potential, Challenges, and Statistical Implications”[1], no qual os autores mostram como o “Big Data” pode beneficiar direta ou indiretamente o acompanhamento de estatísticas financeiras e macroeconômicas através dos seguintes canais: (a) respondendo novas questões e produzindo novos indicadores; por exemplo, análise de sentimento econômico e taxa de desemprego baseados em dados do Facebook e Twitter (O´Connor et. al. 2010; Velikovich et. al. 2010; D'Amuri, 2009)); (b) minimizando a defasagem na divulgação das estatísticas oficiais e servindo como subsídio para prever indicadores já existentes (Nowcasting da inflação (Aparicio et. al 2017; Garcia et. al. 2017) e Nowcasting do PIB (Giannone et. al 2008; Banbura et. al. 2013)) e, (c) fornecendo fontes inovadoras de dados para a produção de estatísticas oficiais (web scraping) para preços e mercado de trabalho, cartão de crédito, Nfe, scanner data para preços e outras estatísticas econômicas). A figura 1 apresenta uma visão geral sobre o potencial do Big Data para o acompanhamento financeiro e macroeconômico.
A análise estatística desse novo conjunto de informações lança desafios com relação às habilidades tradicionais dos estatísticos e econometristas[2]. A tradição de inferência estatística adotada historicamente pela econometria envolve a estimação de relações em modelos especificados a partir de relações comportamentais estabelecidas pela teoria econômica. As informações utilizadas por esse processo de inferência são medidas diretamente quantitativas na forma de amostras aleatórias das variáveis envolvidas. A nova realidade, a partir desse conjunto mais amplo de informações explicitado anteriormente, abrange um conjunto de dados de dimensões muito maiores, muitas vezes não codificados diretamente em termos numéricos, e cuja disponibilidade não necessariamente atende ao ideal de um desenho amostral aleatório.
Como resposta aos vários desafios introduzidos por esta nova realidade, a inferência estatística vem sendo complementada por um conjunto de algoritmos em que a especificação de parâmetros não depende tanto de formas estruturais derivadas de teorias comportamentais quanto do processo de validação de exercícios de classificação e previsão utilizando um amplo conjunto de informações. Este conjunto de modelos e algoritmos existe há algum tempo de forma descentralizada, mas recentemente foi agrupado, sistematizado e refinado, dentro do arcabouço comum que passou a ser chamado de “aprendizado de máquina”.
De uma perspectiva bastante pragmática, os resultados desses diferentes algoritmos aplicados a problemas práticos de previsão, classificação e descobrimento de padrões vêm suplantando, em várias áreas, os resultados de modelos tradicionais de inferência estatística, atraindo uma grande atenção de pesquisadores teóricos e aplicados. De forma geral, esses modelos sustentam a nova geração de aplicações em diferentes áreas denominadas de “inteligência artificial”.
Quanto às “Novas Estratégias Computacionais”, uma condição essencial para a operacionalização dos vários aspectos envolvidos nos dois itens acima é o poder computacional. De fato, a revolução de informação vivida nos últimos anos no mundo só foi possibilitada por uma revolução tecnológica na área de computação digital. Compreender esse movimento é fundamental para que as empresas possam aproveitar as oportunidades atualmente existentes e colocar a instituição novamente como líder em seu papel de criação e análise de estatísticas socioeconômicas, além do ensino e difusão das metodologias envolvidas.
As oportunidades introduzidas por essa nova realidade de informações só podem ser aproveitadas pelos recursos humanos e computacionais essenciais para o processamento desses dados. Neste sentido, um movimento dominante dentro das tendências mundiais ligadas ao Big Data é a utilização de serviços de computação em nuvem. O motivo fundamental para esse movimento é uma ruptura qualitativa tanto com relação aos padrões existentes, tanto de hardware quanto de software.
O ponto central dessa mudança de paradigma envolve a ideia de computação distribuída, essencialmente a solução encontrada para que os processos anteriormente mencionados possam ser factíveis do ponto de vista computacional no contexto de bases muito grandes de informação. De acordo com essa abordagem, os ganhos computacionais necessários são obtidos a partir da divisão das tarefas entre um conjunto de servidores coordenados em vez de um servidor de grande capacidade.
Até aqui, conceituamos o termo “Big data” e, implícita ou explicitamente, mostramos parte dos desafios dessa nova era. Contudo, há três desafios mais evidentes e que merecem destaque: (a) facilidade de acesso aos dados e os novos players; (b) qualidade dos dados e acesso ao Big Data; e (c) novas habilidades.
O aumento exponencial na criação e acesso a novos dados e a possibilidade (a baixo custo) de armazenamento e processamento dessas informações são benefícios proporcionados pelo avanço tecnológico e devem ser usufruídos pela população. Tais avanços, juntamente com a computação na nuvem, permitem que qualquer pessoa e/ou empresa possa coletar, estimar e divulgar uma estatística econômica/financeira e colher os possíveis dividendos dessa informação.
Um exemplo emblemático é o trabalho do prof. Alberto Cavallo que, utilizando técnicas de web scraping, está estimando índices de preços ao consumidor para diversos países, inclusive o Brasil. No artigo “Are Online and Offline Prices Similar? Evidence from Large Multi-channel Retailers”, o autor mostra que está avançando na coleta e no método para a estimação de índice de preços com dados online e que, para alguns países, a relação entre as variações dos preços online e offline é bastante significativa.
Outros exemplos, como o nowcasting do PIB (atualmente a empresa now-casting produz estimativas em tempo real do PIB para diversos países, inclusive para o Brasil) e a produção de indicadores antecedentes e de análise de sentimento dos consumidores (e.g. D'Amuri Francesco 2009; O´Connor et. al. 2010) reforçam a facilidade de acesso aos dados e a participação de novos players na produção de estatísticas.
Quanto à qualidade dos dados e acesso ao Big Data, é importante salientar que a forte demanda por dados mais granulares e em tempo real não pode impedir uma avaliação criteriosa da qualidade dos novos indicadores. É preciso ter atenção aos riscos de se produzir indicadores utilizando dados em larga escala e atentar-se para fatores como: (a) as correlações podem mudar ao longo do tempo, isto é, uma vez que a maioria dos dados são gerados por empresas privadas, o fato gerador da informação pode mudar de acordo com a dinâmica do mercado; (b) não há garantia da sustentabilidade do indicador. Por exemplo, no Brasil as pessoas migraram do Orkut para o Facebook, dessa forma uma estatística baseada naquela rede social perderia validade; e (c) muitos tipos de dados em larga escala não representam uma amostra aleatória da população.
Em que pese a importância fundamental das considerações feitas até o momento, o grande investimento subjacente à mudança de paradigma por trás do aproveitamento das oportunidades trazidas pela realidade do Big Data é relativo ao capital humano.
De um lado, os profissionais da área de TI devem ser aproveitados para realizar a transição gradual entre o modelo existente de estrutura computacional local para o de utilização dos serviços de computação em nuvem, o que envolve o treinamento destes colaboradores para um novo conjunto de habilidades.
É importante atentar-se para a necessidade de se criar times multidisciplinares para fazerem os dados “falarem”. Para manter tais equipes e os chamados “cientistas de dados” (figura 2), é preciso entender que a demanda por esse profissional está muito elevada (“Melhor profissão do ano nos EUA deve explodir no Brasil”) e criar estratégias que possibilitem a continuidade desse time por um período razoável de tempo. Iniciativas como política salarial adequada e plano de carreira em Y[3] para os cientistas de dados são necessárias.

Por fim, recomenda-se a busca de estratégias que possam ajudar a acompanhar as mudanças disruptivas da era do “Big Data” de uma maneira mais célere permitindo que empresas maduras concorram em igualdade com os novos players e que possam adotar as tecnologias que surgem a todo momento.
As opiniões expressas neste artigo são de responsabilidade exclusiva do autor, não refletindo necessariamente a opinião institucional da FGV.
Referências
Alberto Cavallo, 2017. "Are Online and Offline Prices Similar? Evidence from Large Multi-channel Retailers," American Economic Review, American Economic Association, vol. 107(1), pages 283-303, January.
Banbura, Marta, et al. "Now-casting and the real-time data flow." (2013).
D'Amuri Francesco, “Predicting unemployment in short samples with internet job search query data”. MPRA Paper No. 18403, posted 6. November 2009.
Giannone, Domenico, Lucrezia Reichlin, and David Small. "Nowcasting: The real-time informational content of macroeconomic data." Journal of Monetary Economics 55.4 (2008): 665-676.
O´Connor, B., Balasubramanyan, R., Routledge, B.R. and Smith, N.A. 2010. “Fram tweets to polls: linking text sentiment to public opinion time series”, Proceedings of the Forth International AAAI Conference on Weblogs and Social Media, 23-26 May, Washington DC, USA.
Velikovich, L., Blair-Goldensohn, S., Hannan, K. and McDonald, R. (2010), “The viability of web-derived polarity lexicons”, Proceedings of Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, pp. 777–785.
Aparicio, Diego and Bertolotto, Manuel I., “Forecasting Inflation with Online Prices” (June 1, 2017). Available at SSRN: https://ssrn.com/abstract=2740600 or http://dx.doi.org/10.2139/ssrn.2740600
Garcia, Márcio, Marcelo C. Medeiros e Gabriel Vasconcelos (2017). “Real-Time Inflation Forecasting with High-Dimensional Models: The Case of Brazil”. International Journal of Forecasting, 33, 679-693.
[1] Disponível em: http://bit.ly/2CAkXxF
[2] Como exemplo, veja o artigo: Varian, Hal R. 2014. "Big Data: New Tricks for Econometrics". Journal of Economic Perspectives, 28(2): 3-28.
[3] Para maiores detalhes ver: https://www.guiadacarreira.com.br/carreira/o-que-e-carreira-em-y/







Comentários
Deixar Comentário