O aumento da taxa de não resposta – Parte 2: Brasil, PNADC e Censo
O aumento da taxa de não resposta também afetou a PNAD Contínua e o Censo 2022. Como isso afetou e poderá afetar os números dessas fundamentais pesquisas brasileiras e como a divulgação dos dados pode ser aprimorada no futuro?
O que foi descrito na primeira parte deste artigo, publicada em 9/1, terça-feira, neste Blog, é apenas uma pequena parte da discussão sobre a questão da não resposta e de outros desafios enfrentados pelas pesquisas de levantamento ao redor do mundo; para quem quiser se aprofundar, é possível achar um grande disponibilidade de materiais, em especial em journals ou sites de instituições, governamentais ou não, da Europa e Estados Unidos. Porém, não encontramos tantas análises sobre o tema no Brasil, apesar do aumento da não resposta ter sido responsável por uma recente e importante mudança na forma como as estimativas da PNAD Contínua são calculadas, como será visto adiante.
O IBGE lida com uma série de problemas inerentes às pesquisas domiciliares, e a entrevista nos domicílios é apenas a primeira parte de um processo que envolve um tratamento posterior das informações, visando a correção e imputação de dados[1]. A cada mês são pesquisados um pouco mais de 211 mil domicílios em 77 domínios geográficos, entre capitais, Regiões Metropolitanas, Regiões Integradas de Desenvolvimento e o restante das unidades da Federação.
E, já ao longo da própria coleta, algumas correções são feitas com auxílio da programação presente no dispositivo eletrônico usado pelo entrevistador, capaz de captar respostas inconsistentes ou que possam estar erradas (por exemplo, o entrevistado dizer que não sabe ler mas que já concluiu o Ensino Fundamental). Quando um problema é detectado, o entrevistador precisa confirmar ou corrigir o problema com o entrevistado.
Completada a entrevista, os dados passam por dois sistemas; o primeiro verifica se há erros relacionados à categoria de ocupação e à atividade econômica (um respondente que diz dizer ter uma profissão que exige diploma universitário, mas não ter concluído o ensino superior, por exemplo) e o segundo se há valores de rendimento ignorados ou extremos. Constatado o erro, a informação é conferida mais uma vez com quem a forneceu. Passada essa etapa, são utilizados pacotes estatísticos para realizar críticas, correções e imputações de respostas inconsistentes, inválidas e ausentes, e gerados os conjuntos finais de informações dos domicílios. Ou seja, a correção da não resposta de itens é feita nessa fase.
Na fase final, as informações dos domicílios são multiplicadas por pesos, para que se possa chegar aos valores dos recortes geográficos mais agregados; é bom lembrar que a PNAD não foi desenhada para estimar os totais populacionais, mas sim investigar as suas características – em especial aquelas relacionadas ao mercado de trabalho na versão mensal e trimestral da pesquisa – e que as informações obtidas na amostra precisam ser expandidas/extrapoladas.
Para fazer essa expansão e tratar a questão da não resposta de unidade, o IBGE usa uma calibração, sendo que no caso da PNAD é utilizada uma técnica específica chamada pós-estratificação. Envolve a divisão da população em estratos (grupos), em seguida ajustando os pesos da amostra para coincidir com as proporções desses estratos na população total.
Até 2020 esses estratos correspondiam a domínios geográficos. Simplificando, imagine-se que num determinado trimestre a taxa de resposta de todos os domínios geográficos tivesse sido de 100%, e na cidade de São Paulo tivesse sido de 50%. O processo de calibração aumentaria o peso dos domicílios de São Paulo, de forma a fazer com que eles tivessem uma representatividade igual à sua real participação na população brasileira. Essa “real participação”, por sua vez, era obtida a partir das Projeções da População (versão ano de 2018, a última realizada), uma estimativa da evolução do número de habitantes entre um Censo e outro realizada há quarenta anos pelo IBGE, construídas principalmente com base naqueles levantamentos decenais (ao menos teoricamente), em dados administrativos (registros de nascimento e certidões de óbito) e em métodos estatísticos/demográficos.
Mas a ocorrência da pandemia exigiu mudanças em vários procedimentos da PNAD. A primeira foi a substituição das pesquisas presenciais pela abordagem via telefone, em função das medidas de isolamento social (prática adotada em muitos países, ainda que o período da adoção tenha sido diferente), o que acabou causando um grande aumento na taxa de não resposta (ver Gráfico 4).
Isso porque a PNAD adota um esquema de rotação da amostra, no qual um mesmo domicílio é visitado cinco vezes, ao longo de treze meses: o domicílio é visitado em um mês, fica fora da amostra por dois meses e depois volta a ser entrevistado. À medida que domicílios “antigos” saem da amostra depois das cinco entrevistas, é preciso, portanto, que sejam substituídos – mas muitas vezes o IBGE não conseguia o número de telefone do domicílio, impedindo a realização das entrevistas. E, com o passar do tempo, a necessidade de renovação da amostra foi aumentando a influência dos domicílios sem contato.
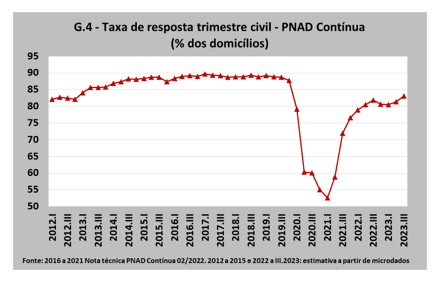
A queda na taxa de não resposta levou o IBGE a fazer estudos estatísticos internos para monitorar a qualidade das estimativas, não encontrando indícios de vieses de não resposta, ao menos para os estratos geográficos mais agregados.[2] Porém, foram detectados dois problemas: o percentual de domicílios unipessoais capturado pela PNAD era menor do que antes da pandemia e a população de catorze anos ou mais (a População em Idade de Trabalhar – PIT) começou a apresentar uma “expansão atípica”, nos termos do próprio instituto, a partir do segundo trimestre de 2020 (ver Gráfico 5).
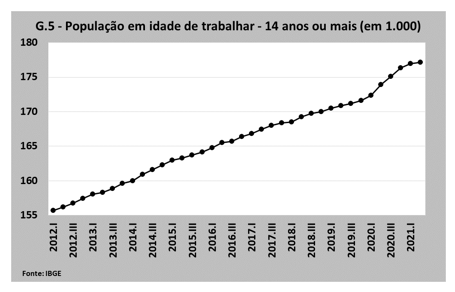
Isso levou o instituto a adotar um novo método de calibração, que reduz o risco de viés de não resposta: a partir do terceiro trimestre de 2021 (retropolados desde 2012), os dados divulgados da PNAD trimestral passaram a ter uma calibração que gera valores compatíveis não só com o total da população para alguns domínios geográficos, mas também com as estimativas por sexo e 17 grupos de idade para o Brasil como um todo, ainda tendo por parâmetro as Projeções da População 2018. Além disso, na realização da primeira entrevista, assim como nos casos em que houvesse recusa ou insucesso nas tentativas de entrevista via telefone, a coleta de dados voltou a ser presencial.
A mudança na forma de calibração pode parecer só um detalhe, mas não é. No Gráfico 6 são mostradas as taxas de participação calculadas pela antiga e nova calibração. A taxa de participação é a relação entre as pessoas com idade de trabalhar e as pessoas que estão dispostas a trabalhar, e é uma variável chave no atual debate sobre o mercado de trabalho brasileiro. Afinal, dada uma mesma quantidade de postos de trabalho, quanto menor for a taxa de participação, menor será a força de trabalho, e menor o desemprego. Ou seja, uma economia pode estar até gerando pouca demanda por mão de obra, mas, se houver pouca gente querendo trabalhar, a taxa de desemprego será baixa.
Uma baixa taxa de participação também gera temores sobre o impacto do crescimento da economia sobre a inflação: se a taxa de participação é baixa, uma demanda adicional por trabalhadores pode não se transformar em maior ocupação, e sim em pressões sobre os salários que poderão ser transmitidas aos preços. É por esse motivo se discute bastante porque as taxas de participação continuam baixas, considerando o nível pré-pandemia e como elas evoluirão a partir daqui.
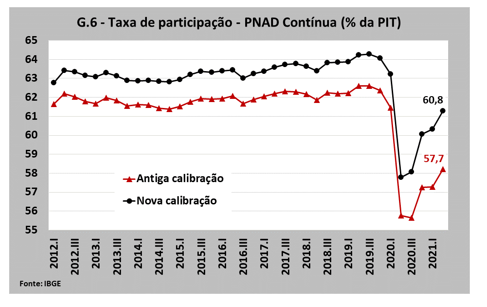
Vale notar, no entanto, que essa alteração na PNAD não teve tanto impacto para a série passada de outras variáveis importantes: a nova calibração alterou todos os valores coletados pela pesquisa, incluindo o total de pessoas ocupadas, de forma que a taxa de desemprego não foi muito revisada.
Mas em breve a PNAD sofrerá mais uma revisão, já que, com a realização Censo 2022/23, uma nova edição das Projeções da População será feita, incluindo uma retroprojeção com as estimativas da população desde pelo menos 2010; logo, os fatores de expansão da amostra terão que ser mudados para refletir os novos valores totais por recortes geográficos e por idade e sexo para o Brasil.
É importante ter em conta que o Censo 2022/23 também foi afetado pela tendência de queda no número de não respondentes: ao final da coleta de entrevistas, verificou-se uma taxa de de não resposta de 4,2 % (total, incluída uma taxa de recusa de 1,4%), quase três vezes maior que a taxa de não resposta total verificada no Censo 2010. As informações desses domicílios, é bom esclarecer, não foram ignoradas, mas sim imputadas através de procedimentos estatísticos. Mas o que levou a tal queda das taxas de resposta?
Na teoria, todo Censo Demográfico deveria atingir o universo da população, mas é muito difícil que isso aconteça em qualquer país. Todos os obstáculos que uma pesquisa domiciliar tem que enfrentar se apresentam também para um Censo, com o agravante de ser uma operação gigantesca, que precisa ser realizada num curto período.
A nossa edição de 2022 (cuja coleta se estendeu até os meses iniciais de 2023), porém, defrontou-se com dificuldades adicionais. Previsto para 2020, o mais importante levantamento sobre a população só veio a acontecer em 2022, em função da pandemia e de problemas orçamentários. E o orçamento finalmente aprovado foi muito inferior ao proposto inicialmente pelo IBGE, o que, combinado a um mercado de trabalho aquecido (e, talvez, à forte ampliação do Auxílio Brasil) tornou difícil a contratação de recenseadores. O plano inicial era contar com um pouco mais de 180 mil pesquisadores, mas, no auge das contratações IBGE, contou apenas com 120 mil. E outros problemas apareceram ao longo da pesquisa: seja por conta de preocupações com a saúde, derivadas da superação recente da pandemia, seja por conta do aumento da violência urbana, muitos domicílios recusaram-se a receber os pesquisadores do IBGE.
Esses provavelmente são os principais fatores a explicar o aumento das taxas de não resposta e recusa acima, que foi verificado mesmo com a fase de entrevistas tendo sido estendida por cinco meses (exceto por algumas ações específicas posteriores). E como isso pode ter afetado os números do Censo?
Bem, os resultados trouxeram bastante surpresa para quem acompanhava os indicadores demográficos. Segundo as Projeções de População 2018, a população em agosto de 2022 estaria em torno de 215 milhões. Em dezembro de 2022 uma divulgação preliminar do Censo 2022/23, realizada para poder atender à necessidade de repartição de fundos federais com estados e municípios, apontou uma população 207,8 milhões, já portanto bem abaixo do previsto pelas Projeções da População 2018. E os números definitivos (203,1 milhões) divulgados em meados de 2023 revelaram uma diferença ainda maior.
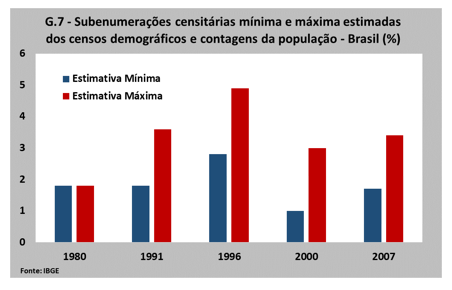
Dados todos os problemas pelos quais passou o Censo de 2022/23, é legítimo considerar alto o risco de que essa edição tenha um problema de subenumeração (a subestimação da população) acima da média das edições anteriores. Conforme comentado, é virtualmente impossível que qualquer Censo entreviste toda população, e o IBGE há muitos anos utiliza procedimentos estatísticos e demográficos para estimar essa subenumeração[3] no Brasil – chegando a um valor médio de 2,3%, considerando a faixa mínima e máxima calculada por métodos diferentes e excluindo os valores da Contagem de 1999, cuja cobertura foi reconhecidamente muito baixa (ver Gráfico 7).
E em quanto os números do Censo poderiam estar subestimados? Em post publicado em setembro de 2023 no blog do IBRE[4], apresentamos um primeiro exercício utilizando dados administrativos (como os registros de nascimento e certidões de óbito) para estimar uma possível magnitude da subestimação, considerando o total da população.
De lá para cá, foi possível aprimorar o exercício, acrescentando, em primeiro lugar, a comparação por faixas de idade – o que possibilita abordar possíveis vieses de não resposta. E, em segundo lugar, incluindo estimativas sobre fluxos migratórios internacionais (calculadas a partir de informações disponibilizadas pelo Observatório das Migrações Internacionais), seguindo raciocínio do demógrafo José Eustáquio Diniz Alves, que também utiliza dados administrativos na análise dos resultados do Censo 2022[5]. Para chegar ao fluxo migratório líquido, inicialmente subtraímos, do total de registro de brasileiros que saíram do país, o total de registros dos que voltaram; posteriormente, somamos o número de vistos concedidos a estrangeiros, mas apenas os vistos classificados como de “Residentes”, desconsiderando os outros dois tipos que indicam estadias de curto ou curtíssimo prazo (vistos do tipo “Temporário” e “Fronteiriço”).
Os valores são apresentados na Tabela 1, sendo que, por questões relativas à disponibilidade de dados, a população resultante do exercício e a das Projeções da População 2018 refere-se a 1º de julho de 2022, enquanto a do Censo 2022 refere-se a 1º de agosto daquele ano.
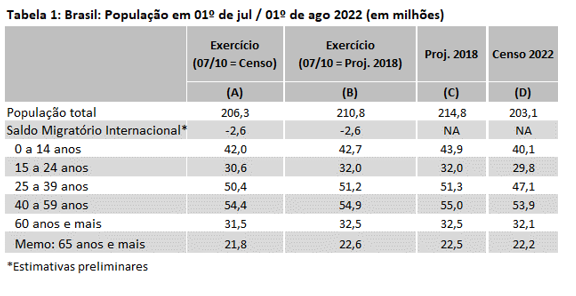
A coluna (A) traz a estimativa da população em julho de 2022 a partir da aplicação dos registros administrativos sobre os valores de julho de 2010, sem considerar nenhum ajuste de subenumeração. Ou seja, aqui são somados os nascimentos, subtraídos os óbitos e acrescido o fluxo migratório sobre as informações originais do Censo 2010, segundo as quais a população em julho de daquele ano era de 190,8 milhões de habitantes.
Os dados da coluna (B) também foram calculados via a aplicação dos registros administrativos, mas tendo como ponto de partida os valores de julho de 2010 correspondentes aos fornecidos pelas Projeções da População 2018. Cabe notar que aquelas Projeções ajustaram os números do Censo 2010, estimando que a população em julho de 2010 não seria de 190,8 milhões de habitantes e sim de 194,9 milhões (2,2% maior), valor no qual depositamos maior confiança dado o histórico de subenumeração dos Censos segundo o IBGE.
Na coluna (C) são apresentados os valores das Projeções da População 2018, enquanto na coluna (D) encontram-se os valores do Censo 2022/23 publicados no segundo semestre do ano passado. As estimativas por grupo etário dos exercícios não consideram valores do saldo migratório internacional, porque ainda não foi possível estratificá-los; por isso essa variável foi imputada considerando o total de indivíduos, sendo necessário estudos adicionais para compreender algumas das características e limitações da estatística. Em função da avaliação sobre o valor de partida (julho de 2010) citada acima, iremos comparar apenas os números das colunas (B), (C) e (D).
A utilização dos dados administrativos indica que a população brasileira em meados de 2022 estaria em torno de 210,8 milhões de pessoas, o que significaria uma superestimação das Projeções da População 2018 em 4,0 milhões de habitantes – o que ocorre por dois motivos. O primeiro: em 2018 não se considerava, por óbvio, os impactos da pandemia sobre o número de óbitos no triênio 2020/2022 (ver Gráficos 8 e 9); o segundo: aquelas projeções assumiam que o fluxo migratório internacional líquido seria praticamente zero no período, mas os números oficiais indicam que este saldo foi negativo, aproximando-se dos três milhões de pessoas. Cabe ressaltar que esses números são preliminares, e que ainda estamos estudando a base de dados do Observatório das Migrações Internacionais para dirimir algumas dúvidas metodológicas. Uma avaliação preliminar indica que talvez o saldo líquido negativo possa ser um pouco menor, mais próximo dos dois milhões de habitantes.
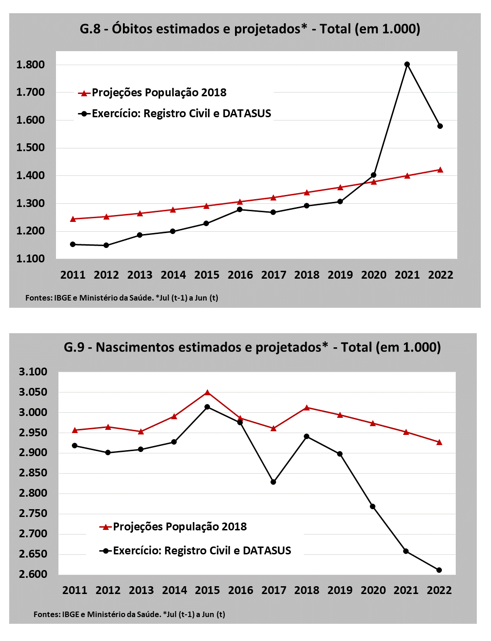
Por outro lado, o exercício indica que os números do Censo 2022/23 estariam subestimados em 7,7 milhões de habitantes; isso representaria uma subenumeração censitária de 3,8%, bem acima da média histórica, mas compatível, em nossa opinião, com as particularidades do último levantamento “decenal”.
O mais importante dessa atualização do exercício, porém, é a análise por faixas de idade, e o que nos conecta à questão da não resposta. A Tabela 2 traz a relação entre os dados do último Censo e os do exercício com o uso dos dados administrativos que aparece na coluna (E) da Tabela 1. O valor da célula que aparece na coluna (E) correspondente à linha “População Total” (96,3) indica que o valor do Censo 2022/23 para a população total é 3,7% inferior ao obtido pelo exercício com registros administrativos.
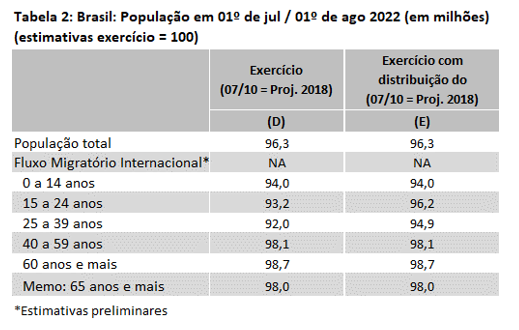
O que chama atenção é o fato de que a diferença obtida para as faixas etárias referentes aos mais idosos é bem menor do que a diferença referente as faixas etárias referentes aos mais jovens: enquanto no caso dos maiores de 60 anos o valor do Censo 2022/23 é apenas 1,3% inferior ao obtido pelo exercício, no caso da população de 25 a 39 anos o valor do Censo 2022/23 é 8,0% menor do que aquele obtido através do exercício.
Alguém poderia argumentar, e com razão, que provavelmente os brasileiros que saem do país se concentram nas faixas etárias mais jovens. Por esse motivo, fizemos uma simulação (coluna (E)) na qual os 2,6 milhões referentes ao fluxo migratório internacional (negativo) foram retirados das faixas etárias “15 a 24 anos” e “25 a 39 anos”. Ainda assim. a diferença percentual continua menor no caso dos idosos.
Essa diferença na comparação das faixas é importante porque há relatos na literatura mostrando que domicílios em que há idosos ou com mais pessoas a taxa de não resposta a pesquisas tende a ser menor, devido ao maior tempo de presença das pessoas mais velhas em casa[6]. Ou seja, há aqui um indício de que as dificuldades enfrentadas pelo Censo podem ter levado não só a uma subenumeração, mas também um viés de não resposta cuja consequência é revelar uma população mais envelhecida do que ela realmente é.
Convém lembrar que: i) um dos aspectos que mais foram destacados na divulgação das informações sobre o perfil etário da população brasileira foi o aumento do índice de envelhecimento da população brasileira; ii) tal informação já deu início à discussão sobre a necessidade de uma nova Reforma da Previdência; e iii) a nova forma de calibração da PNAD torna relevante os dados por faixa de idade das Projeções de População, que usam como insumo os dados do Censo Populacional. Diante desse quadro, vale a pena refletir se há algumas medidas que possam ser sugeridas a partir de agora, no que se refere à forma como os dados populacionais e dos mercados de trabalho e suas estimativas futuras serão divulgadas.
Algumas sugestões sobre a forma de divulgação dos dados populacionais e da PNAD
De tudo o que foi visto em relação à experiência internacional, é provável que a taxa de não resposta da PNAD possa até reverter para um nível menos pronunciado, mas não deverá retornar ao patamar pré-pandemia. Por isso, seria interessante que o IBGE passasse a divulgar a evolução dessa variável, sem que os usuários precisassem recorrer aos microdados. É verdade que tal procedimento teria um lado negativo: fazer com que os desavisados interpretassem a não resposta como um indicador de viés. Por outro lado, isso daria aos analistas, a quem realmente olha os dados no detalhe e os interpreta, a possibilidade de melhorar a compreensão das informações.
Um ótimo exemplo a seguir seria o do Bureau of Labor Statistics (BLS) dos Estados Unidos, que no seu site (https://www.bls.gov/osmr/response-rates/) não somente disponibiliza as taxas de todas as pesquisas, mas até as dividem por tipos de levantamento, a fim de que o usuário possa interpretar as taxas de não resposta, além de disponibilizarem, quando há, textos interpretativos.
Outra iniciativa que o IBGE poderia tomar seria divulgar a taxa de imputação utilizada. No texto de discussão “O tratamento das informações da PNAD”, por exemplo, aparece o seguinte gráfico:
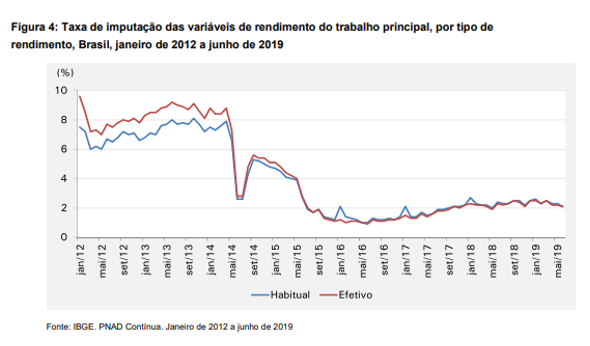
Quem viveu o período de fim da antiga Pesquisa Mensal de Emprego (PME/IBGE) e a sua substituição pela PNAD Contínua talvez se lembre da dificuldade em compreender a diferença apontada pelas duas pesquisas para variáveis muito importantes. Atualmente, os analistas, tanto do setor privado quanto do setor público, têm se debruçado sobre certos comportamentos do rendimento do trabalho difíceis de explicar. Informações tempestivas sobre a imputação, e que também não dependam de manipulação dos microdados, possibilitariam avaliar o quanto a evolução decorre de fenômenos econômicos e o quanto pode decorrer de procedimentos para lidar com a não-resposta.
Destaque-se que essa preocupação com o papel da imputação pode vir aumentar sua importância na avaliação das oscilações dos dados. A despeito da disponibilidade de dados, um relatório de órgão de auditoria do BLS[7], divulgado em outubro de 2023, afirmou:
O BLS tomou medidas para enfrentar os desafios colocados pela diminuição das taxas de resposta à pesquisa. No entanto, o BLS poderia fazer mais para identificar possíveis limitações dos dados em suas informações econômicas e aumentar a transparência dessas limitações. Não foi possível identificar uma correlação entre os custos e o declínio das taxas de resposta à pesquisa. Para reduzir o impacto da falta de dados causada pelo declínio das taxas de resposta à pesquisa, o BLS aumentou o uso de imputações em seus dados de pesquisa, que são essencialmente dados de substituição inferidos a partir de informações relevantes disponíveis. Embora as imputações sejam uma prática padrão entre as agências federais de estatística, o BLS poderia ser mais transparente quanto ao aumento do uso de imputações para facilitar a interpretação precisa dos dados de seus levantamentos. (...) É necessária maior transparência em relação a possíveis limitações de dados para garantir que os usuários da pesquisa de BLS tirem conclusões corretas dos dados ao tomar decisões críticas, como mudanças de políticas que afetam o povo americano.
Ainda a respeito da imputação, o ideal seria a PNAD contar com relatórios de qualidade como os do Office for National Statistics (ONS) do Reino Unido, que traz um detalhado relato do número de respostas, causas de não resposta e valores de variáveis com e sem imputação, entre outras informações (ver o Labour Force Survey performance and quality monitoring report, no site do órgão, que traz também dados em planilhas).
Um segundo produto do ONS cuja replicação no Brasil seria muito bem-vinda é o relatório Measures showing the quality of Census 2021 estimates, um relatório que, tal como o relativo ao Labor Force Survey, permite um detalhamento das estimativas numéricas de imputação. Isso permitiria ao usuário ter acesso mais fácil ao impacto das taxas de não resposta, inclusive em relação aos recortes regionais.
No que se refere às Projeções de População, por fim, ficam duas sugestões. Em primeiro lugar, a de que se tente considerar os dados administrativos sobre imigração internacional. Há certamente limitações, como a aparente ausência de informações sobre idade e local de residência dos brasileiros que deixam o país, o que tornaria necessário a utilização de algum tipo de imputação, mas a hipótese de que o saldo líquido negativo é nulo utilizada na Revisão 2018 parece ser muito forte. Em segundo lugar, talvez valha a pena o IBGE, antes de calcular as estimativas finais do Censo 2022/23, realizar um seminário (como já foi feito em outras ocasiões), debatendo os procedimentos e colhendo as dúvidas e sugestões de usuários.
Esta é a segunda e última parte do artigo de Francisco Pessoa Faria sobre o problema da não resposta em pesquisas, cuja primeira parte foi publicada neste Blog em 9/1/2024.
As opiniões expressas neste artigo são de responsabilidade exclusiva do autor, não refletindo necessariamente a opinião institucional da FGV.
[1] O texto para discussão O tratamento das informações da PNAD, de Baptista, Fernanda K. R., Hypólito, E. B., Conde, F. Q. - Rio de Janeiro: IBGE, 2022. (Textos para discussão. Diretoria de Pesquisas n. 61), um interessante detalhamento do processo de correção e imputação de dados na PNAD.
[2] Ver notas técnicas PNAD 2021 (nos. 01, 02, 03 e 04). https://www.ibge.gov.br/estatisticas/sociais/populacao/9171-pesquisa-nac...
[3] Ver “Os levantamentos censitários: níveis e padrão histórico de subenumeração populacional.” in Projeção da População por Sexo e Idade – 1980-2050 Revisão 2008. Rio de Janeiro: IBGE, 2008. (Série Estudos & Pesquisas - 24)
[7] “BLS could do more to identify data limitations and increase transparency” U.S. Department of Labor - Office of Inspector General Audit – Report to the Bureau of Labor Statistics (2023).







Deixar Comentário